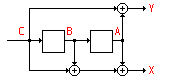
In this section, it is assumed that a data stream has passed through the above circuit to yield a series of two bit (dibit) symbols representing the data. It is now necessary to examine the incoming bits and to extract the original data. Of course, the symbols received may not be exactly the same as those which were originally transmitted.
Assume the circuit starts at 00, and recall the table defining the behavior of the encoding circuit:
THIS -------------> NEXT STATE STATE BA -C--> CBA=(XY) next BA ------------------------- 00 -0--> 000=(00) ===> 00 00 -1--> 100=(11) ===> 10 ------------------------- 01 -0--> 001=(11) ===> 00 01 -1--> 101=(00) ===> 10 ------------------------- 10 -0--> 010=(10) ===> 01 10 -1--> 110=(01) ===> 11 ------------------------- 11 -0--> 011=(01) ===> 01 11 -1--> 111=(10) ===> 11 ------------------------- |
From an initial state of 00, the expected symbol can be 00 or 11, depending on whether a '0' or '1' was transmitted.
The received symbol is 11, so it is concluded that the data bit is '1' and the new state is 10.
From the current state of 10, the expected symbol can be 10 or 01, depending on whether a '0' or '1' was transmitted.
The received symbol is 10, so it is concluded that the data bit is '0' and the new state is 01.
From the current state of 01, the expected symbol can be 11 or 00, depending on whether a '0' or '1' was transmitted.
The received symbol is 11, so it is concluded that the data bit is '0' and the new state is 00.
This process continues to recover the message as:
Finding the Best Path
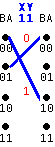 |
Alternatively, the data can be recovered by identifying the path through the trellis defined by the sequence of symbols. This approach leads to a more robust and systematic approach to finding and correcting bit errors. From the above table, it can be noted that the first symbol '11' could represent the data bit '1' on a path leading from state 00 to 10, or the data bit '0' on a path leading from state 01 to 00. These two possibilities are summarized on the sketch at left, for the symbol '11'. The original data bit associated with a given symbol depends on the current state BA. When all the possibilities for all the received symbols are shown together, as shown below, a distinct path through the trellis can be identified which immediately gives the correct data bits. This path will be continuous if there were no errors in the incoming symbols. |
| Each received symbol (XY) could represent either a '1' or a '0' depending on the current state of the circuit (BA). The correct data bits describe a continuous path through the trellis. The final answer is shown below. | |||||||||||
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | |
| Decoded Data Bits (continuous path) | |||||||||||
The problem is obvious if the symbols are simply accepted as received:
| 1 | 0 | ? | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | |
| Errored Data Bits (no continuous path) | |||||||||||
It is necessary to reconstruct a continuous path from the above information. The "best fit" path will be the one which best matches the above data, deviating only as required to establish continuity. The available resources to establish this path are the four possible symbols and the corresponding eight possible state transitions:
| Available elements to establish a continuous path | |||||||||||||||
The simplest correction, and the one which yields the correct answer, is found by inspection in this case. If the symbol '11' with data bit '0' is used for the third element, the problem is repaired and the data bit '0' is recovered. The restored path is shown below.
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | |
| Corrected Data Bits (continuous path) | |||||||||||
It can be seen that that there is a single bit difference between the (incorrect) path which was received and the repaired path which was computed. The Hamming distance is 1 between these two paths. This reflects the fact that a single bit error caused the problem.
RECEIVED DATA:11 10 10 11 01 10 01 00 01 01 11
REPAIRED PATH:11 10 11 11 01 10 01 00 01 01 11
================================
DIFFERENCE:00 00 01 00 00 00 00 00 00 00 00
Although the above result seems obvious, alternative corrected paths can also be imagined. Other possibilities, and the chance of multiple bit errors must be considered, since it cannot be known in advance where the error occured. Consider the following proposed correct path.
| 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | |
| Alternative Continuous Path | |||||||||||
So what makes this path any worse than the above answer? The answer lies in the Hamming distance between the proposed path and the actual received symbols. As shown below, this new path lies a distance of 6 from the received data. This suggests that if this path were correct, these exact six bit errors would have had to occur. Statistically, it is expected that a single bit error (the previous result) is much more likely to have occured than six bit errors side by side. For this reason, this approach is sometimes called the "maximum liklihood" method. The second path must be discarded in favor of the previous result which was clearly the most likely occurence.
RECEIVED DATA:11 10 10 11 01 10 01 00 01 01 11
PROPOSED PATH:11 01 01 00 01 10 01 00 01 01 11
================================
DIFFERENCE:00 11 11 11 00 00 00 00 00 00 00
Performing the above operations on very long data streams would not be very efficent. The topic of Viterbi Decoding is examined in the next section.