|
|
 |
 |
|
 |
 |
|
|
|
 |
|
 |
 |
|
|
|
 |
|
 |
|
|
|
|
|
Automatic Document Classification Using Artificial Intelligence
|
|
|
In the information age, with the rapid growth of Internet and electronic document resources,
automatic document retrieval systems are becoming more important. Humans can recognize words like
"sports" or "politics" by glancing at an article without reading the whole text in order to classify
documents. However, when millions of files are involved, we cannot rely on human-beings to go through
all the documents. Especially when no keywords are listed for the articles. In the information age, we
need computer systems that can complete document classification tasks automatically. For document
classification, we need a reliable automatic classifier to tag electronic files for separate categories.
Such a classifier can be used at libraries, educational institutions, governments and businesses having
large amounts of customer data or documents, and IT companies that have to access huge amounts of data online.
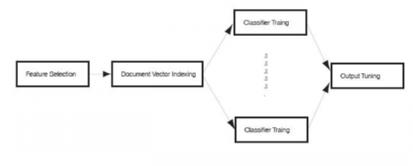
In the proposed research project, an intelligent document classifier will be built where the information
gain method will be used for feature selection tasks of the classifier. The developed classifier will
select words from a document that contain more information to separate this document from others. The
weights of the vectors describing the words will be evaluated. If a word is distributed over more documents
in the selection, its weight should be lower because it does not contain much information to classify the
documents. Artificial intelligence will be used to train the developed classifier. Because of the information
contained in the selected words, the learning efficiency of the developed classier will be very high. The
classifiers will be tested using a standard database online. Thousands of documents will be selected to
train the classifier and five to ten thousand documents will be selected as the test set. The effectiveness
of the developed classifier will be demonstrated by comparison studies. Two standard performance measures
will be used to evaluate the performance of the classifier.
|
|
|
| |
|
